SRE
SRE概念
2016年Google提出的概念,需要的技能跟IT或MIS很像所以很常有人誤會是一樣的,甚至造成隱形衝突導致薪資不符合期待。
公司需求分成兩個部分
- 內部需求:服務公司內部系統、網路、電腦設備,內部資安管控、、員工教育訓練、設備採購、資安風險,BPM業務流程管理,多半是IT或MIS處理
- 外部需求:產品開發與維運, Devops、OP、SRE、Infra,CI/CD、系統監控、事件管理(Incident Management)、SRE又增加自動化與架構設計
1. 維運團隊的普遍現象
1.1.1 SRE職能錯誤期待
google提出的關鍵指導原則是:擁抱風險、錯誤預算、服務水準目標、SLI、SLO、SLA,減少瑣事、透過時間槓桿用50%的時間,開發自動化維運工作,製造出飛輪效應。 Ops as Code 也就是用軟體工程提高系統維運任務的效率。
飛輪效應:一開始阻力很大,但是克服之後當每一圈的動量與動能達到一個程度後,要讓他在短時間內停下來的外力會更大,能克服較大的阻力維持原有的運動。
工程師通常都身兼多職,所以讓這類工作模糊,把整套工作多一個專門的人處理,更宏觀、縝密的規劃架構
敏捷開發:透過固定時間迭代的持續改善、讓軟體開發複雜的過程穩健前進,最後產生速度感
透過 固定周期、 刻意練習、 反饋迴路 達到 持續改善
PS:目標成為: 規劃與設計者【執行貢獻者】:個人特質有
- 獨立思考
- 跨部門協作
- 格局視野
- 溝通技巧
- 技術含量
SRE針對 大流量的產品系統,比較有發揮空間,技能天花板也比較高不怕沒有工作。
1.2 自動化其實是個錯覺?
自動化的動機
- 降低人為疏失,提高SOP效率、系統的可靠性
- 提高執行效率,降低人力成本與系統金錢成本
- 軟體工程提高
可複用性(Reusable)、增加產能
人管系統,系統管機器
關鍵因子:負反饋迴路
火箭的機制就是透過【負反饋】不斷修正自己的軌道,以確保抵達最終目標
透過一堆的感測器取得外在因素(溫度、風速、氣壓)轉換成訊號,回授(Feedback)之後再給輸入單元並處理,一整個迴圈
graph LR;
classDef default fill:#ECECFF,stroke:#9370DB,stroke-width:2px,color:#000
A[input]-->B[Process];
C-->D[Feedback];
B-->C[Output];
D--溫度/風速/氣壓-->A;
1.2.2 理想:怎樣才是自動化監控系統
除了監(watch)、正重要的是控(Control),控就是透負反饋的迴路觸發行為
蒐集指標、觸發條件、發動警報。
最難的是在分析
graph LR;
classDef default fill:#ECECFF,stroke:#9370DB,stroke-width:2px,color:#000
A[input]-->B[Process];
B-->C[Output];
B-->D[Logging/Metric];
D--> E[Conditions]
E --> F[Analyze];
F -->G[Actions];
G-->B;
1.2.3目的:自動化是為了讓系統具備可靠度
- 需求定義:期望的關鍵成效、服務水平協定(SLA)、服務目標(SLO)、服務指標(SLI)
- 系統分析:明確定義使用者、輸入、輸出、使用者情境
- 系統設計:包含API設計、Configuration/Ioc、架構設計、部屬策略、可靠度設計、監控指標設計等
- 程式開發:物件導向、單元測試、開發規範、系統架構
- 測試策略:測試方法、系統架構、功能測試、非功能測試、整合測試
- 監控與異常:設計監控指標與警報、事件管理、異常處理
- 品質:品質是整個過程,有效率的演算法、良好的工程習慣以及對品質的堅持。
1.3 維運需求與價值的選擇
下圖是實際狀況,P1~P4是優先順序
需求量如果一樣多,那些被排擠到哪去?其實就是技術債,就是多出來的部分。
重要、不急 但不做,時間久了就會變成 【重要、緊急】
這些處理起來通常非常HardCode,需要長期磨練跟經年累月養成。會造成這種狀況多半是 短期解填補,然後就沒有然後了。
千金難買早知道:早知道,值千金
SRE 在 ABC,一般開發者在 ADC,雙方交疊的是A跟C,下圖是想要表達長期公司的 【產品團隊】與【維運團隊】比例嚴重不足,10:1或20:1,甚至100:1或200:1,這對團隊長久來說會是硬傷。

疊加問題 1 + 2延伸問題
- 任務無法有效執行:只處理事情表面卻無法根除,維運人員每次在異常事件中,
無法累積經驗成長 - 人力與管理問題:爆肝、士氣低落,看不到職涯願景、離職
- 技術債直線上升:沒有機會處理、沒資源,對組織沒有認同感與向心力
1.4.2缺乏技術管理的決策者
技術債這麼多,背後本質是技術管理的問題組織由誰來做這個【技術決策】?
決定組織【如何選擇】團隊技術方向的過程
- 決定並滿足企業的需求
- 滿足團隊【現在】與【未來】的
技術方向
聽起來是CTO或副總或架構師或資深人員,但其實要決定的是幾件事情
-
企業
現在與未來的需求 -
團隊現在的駕馭能力與未來的需求
體現下面兩個因素 -
很了解自己的需求,不瞭解自己的需求
-
能駕馭工具、不能駕馭的工具
由誰來決策? 可以用來影響力來判斷決策者, 大部分會想到高權力、CTO、架構師但真的是這樣嗎???
畢竟現在很多技術:分散式系統、快取、資料高可用、這些CTO真的懂嗎?
2. 維運時間殺!SRE需要制度
2.1 SRE為何而戰?
2.1.2 需求類型
- 功能:對使用者(客戶)直接帶來價值的功能,直接影響使用者購買意願。把客戶帶進來
- 非功能:不能直接帶來價值,但卻影響使用者意願。把客戶留下來
- 店購瞬間流量搶購,高併發工程增加可靠性
- 防禦DDOS
- Auto Scaling機制
- 針對硬體故障的高可用架構(HA)
- 提升可靠度的k8s
- 容錯機制的 Chaos Engineering
- 提高系統使用率,節省IT費用
2.1.3 需求源頭
誰提出的(解決誰的困擾)

2.1.4 SRE 需求功能
- 服務企業的客戶
- 系統出現異常的時候,SRE在最短的時間內止血,讓系統恢復正常運作
- SRE確認整個請求鏈路(Request Chain)的哪裡出問題。經常是
I/O Blocking造成資料庫查詢效能不好、存取盪按時磁碟反應慢、Deadlock資源競爭 - 上帝視角確認問題
- SRE確認整個請求鏈路(Request Chain)的哪裡出問題。經常是
- 系統出現異常的時候,SRE在最短的時間內止血,讓系統恢復正常運作
- 服務企業內部的產品開發團隊
- 擔任顧問角色
- 釐清系統架構、找出架構問題,像是內外部依賴關係、通訊協定、應用程式的Config、Logging
- 服務自己的團隊
- 透過軟體的辦法讓系統變得更可靠
- 自助式的CI/CD,讓開發團隊依照實際狀況透過(GitLab/ Jenkins)決定執行藍綠切換或是回滾(Rollback);或是指定部署的版本或區域
- 服務企業
- 每天:資料庫完整備份、Log備份、虛擬機備份、刪除舊的備份
- 每週:了解系統狀況,個指標是否異常,不符合SLO定義的,備份狀況檢查
- 每月:系統監控趨勢複查、成本複查、軟體更新、網路流量複查
- 每季:作業系統資安更新、軟體套件更新資安更新、Public IP管制列表、資料還原演練,系統異常演練、架構複查、權限複查等
- 每年:防災演練、網路防火牆複查、資源使用政策調整、防火牆政策、網路拓樸架構負複盤、SSL購買
2.2 制度:讓維運團隊自主運作的制度框架
一個框架可以讓團隊自己動起來,不論企業在哪個階段都要面對如何有效做好系統維運
再有限的人力之下(三人以下),同時維運眾多服務,能夠逐步執行維運系統的任務。
- 個人角度:累積與重複使用,每次跌倒都有成長
- 團隊
- 有限資源下,滿足On Call需求大家才能安心放假,避免公車效應(某個關線人物出意外導致整個專案無法進行)
- 有章法、組織性、有陣型的執行任務,才可以規模話、系統化。
- Design for Operation 不是口號,是平常就在做
- 傳承、知識共享
- 企業:減少成本、提升可靠度、擴展業務
2.2.1 制度與框架
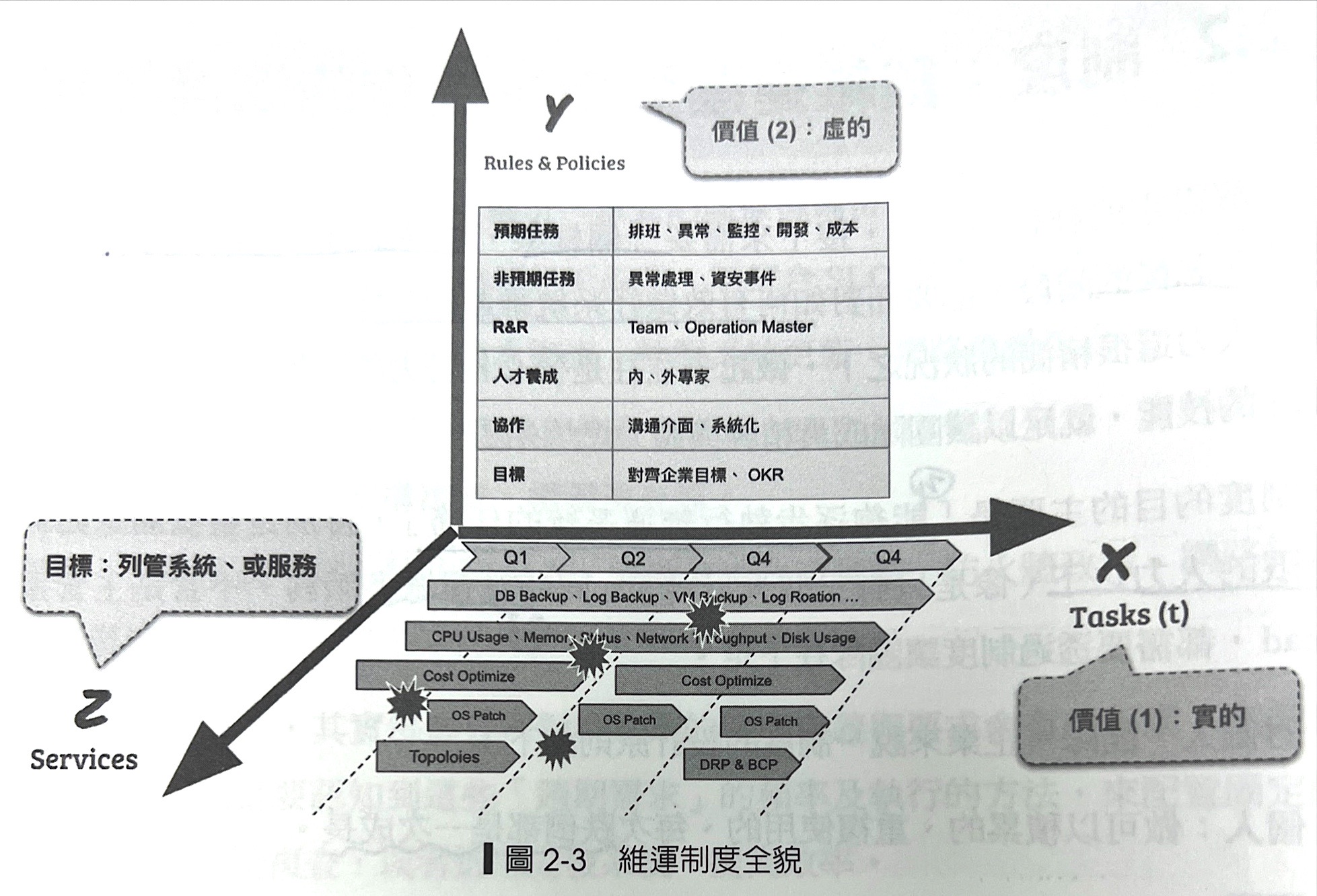
X軸很具體任務,容易定義成敗;Y軸定義遊戲規則偏向管理面,但卻是讓團隊能長期運作與增長的方法,前者實、後者虛,虛實融合才可以讓團隊走得長遠,同時具備 面對改變`的能力
X軸
具體的任務(Task),間接顯示每個里程碑的概念,任務區分
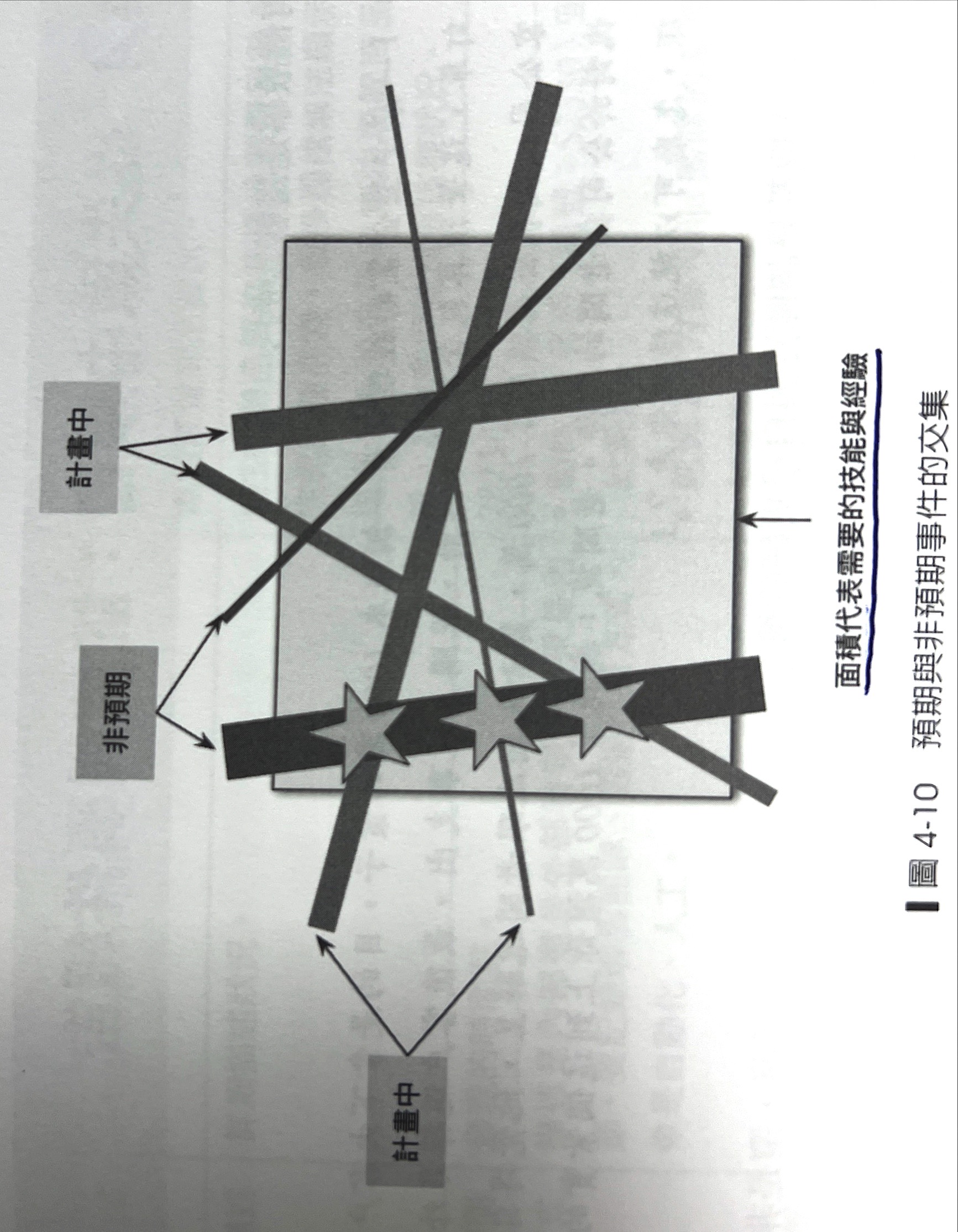
- 【預期】:週期性、跟產品職皆有相關
- 【非預期】:臨時性,途中爆炸圖案
Y軸
制度與政策,覆蓋了所有維運範圍
- 任務:週期性、預期、非預期、開發工作等
- 週期性任務通常已經有SOP
- 第一次做週期任務,完成任務後也要產生新的SOP
- 重複做的SOP完成任務要檢視是否需要
重構SOP或改善SOP - 非預期任務,異常處理需要有異常報告,描述異常的始末(並不是每個人都有機會處理意外,深入研究並剖析之後報告,可以最快讓大家吸收知識)
- Roles And Responsibity(角色與責任)
- 內部團隊,整個是一個Pool 所有人都要作為運任務
- 地易Operation Master
輪流擔任的協調整,負責協調任務與資源 - 負責開發自動化的SRE:利用
50%的時間來開發成是,提高維運效能
- 任務角色配置
- 有人負責執行,有人負責檢驗,有人負責後勤支援,大家一起產生行動,攻守並重
- 每次任務需要有
明確的時間軸、行動、檢核時間點 - 遵循PDCA
- 人才養成
- 每個領域知識(Domain knowledee)中,需要有兩位以上的專家
- 每個專業知識(Technical Knowledge)中,需要有兩位以上的專家
- 兩個領域最好有兩位以上的
外部專家 - 掌握領域知識與專業知識清單,進行人才培養
- 協作
- 明確SRE團隊與其他團隊的關係人定義,確保團隊之間的連結(Connect)
- 確保與其它團隊關係人的溝通方式是順暢且透明的,透過
Issue Tracking System,公開系統管理,誤用Email、Line、Skype
- 目標
- 確保團隊目標與公司、與產品、與人一致
Z軸
(已列管 + 未列管) X 部署的環境
維運的範圍,通常與X軸一起看,一個產品有非常多服務,應該會有一個任務清單
- 已列管:大家都知道的、明確的系統資訊、監控機制、服務依賴關係、權責定義
- 未列管:規劃中、尚未被確立、短時間內不會出現再列管清單
服務意旨:API、DB、Endpoint.....業務上獨立的像是 訂單服務、商品服務,是由一個獨立團隊負責開發。
SRE這邊除了正式環境,測試環境也需要被考慮到
看清楚系統的範圍、部署數量、才能掌握全貌,SRE負責全部系統的維運、從上線中到上線
- 上線前:
環境建置、網路賤價構、資料庫建置 - 上線中:
部署策略規劃,藍綠部署、Rolling Update、Auto Scaling - 上線後:監控系統、異常處理
以下就針對 上線 前中後來進行更細部的說明
2.2.3上線前的充分準備
上線前第一次上線服務或每次迭代更新的服務
這類服務都需要SRE直接或間接處理,不管是哪一種都要根據實際狀況去做準備工作、人員訓練、系統架構、團隊溝通。
針對已上線的就是用【系統架構】了解現況、關鍵指標與趨勢,或從過往的異常報告來了解歷史。
上線前需要了解系統架構、服務關鍵指標、過往事件報告
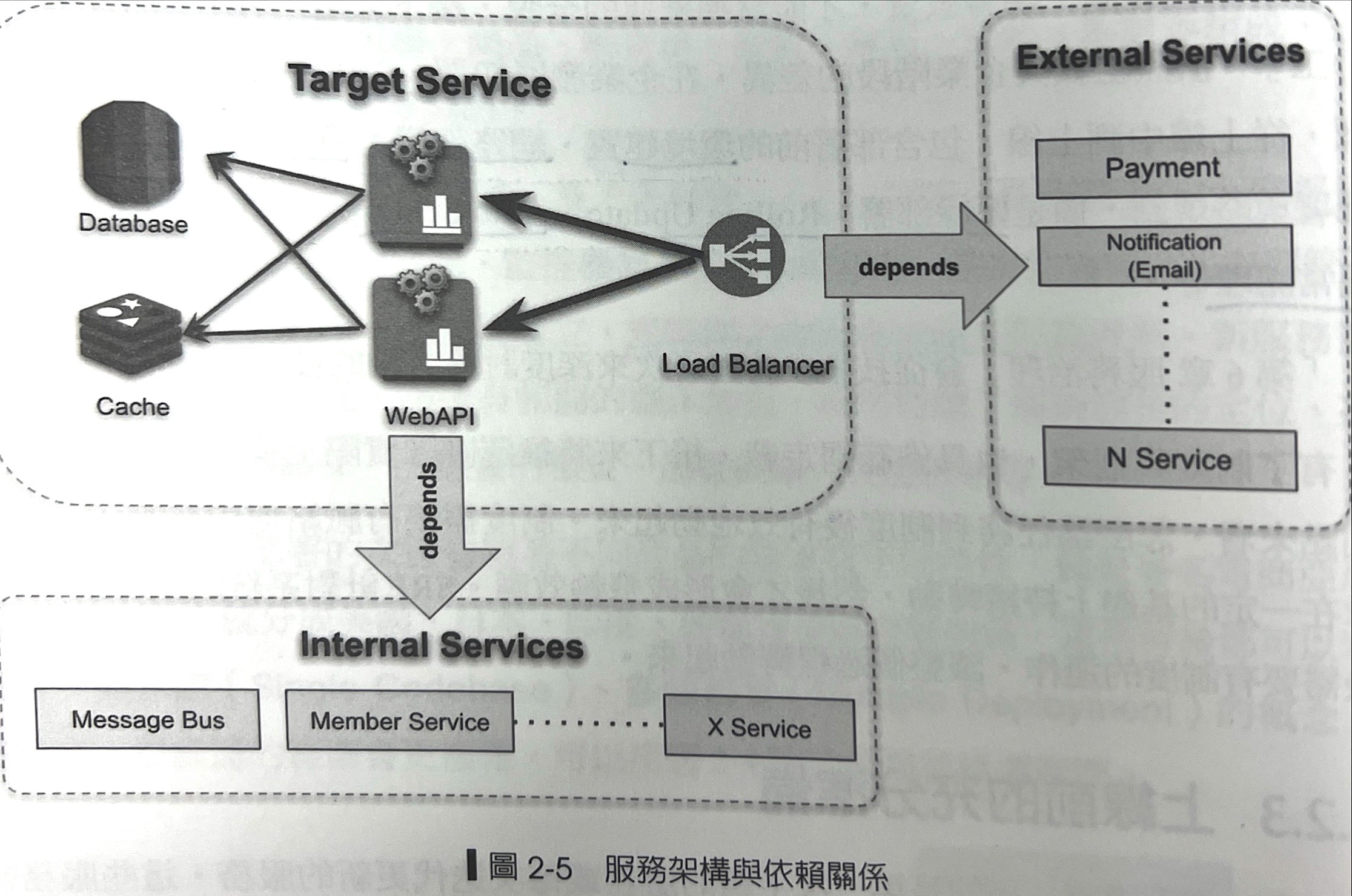
系統架構包含Web Service的API、Database、Cache、Load Balancer等角色構成,除了角色還又內外部依賴,像是支付系統、通知系統,內部搭Message BUs、會員服務。
以下是範例圖:
系統架構圖
關鍵指標
整個系統的外再資訊,依照服務特性再設計階段(System Design,SD)定義需要的業務關鍵指標(Domain Key Metrics、DKM)以及系統關鍵指標(System Key Metrics,SKM)
業務關鍵指標
以電子商務為例子就是【訂單服務】為例子,每個訂單都有它的關鍵狀態。
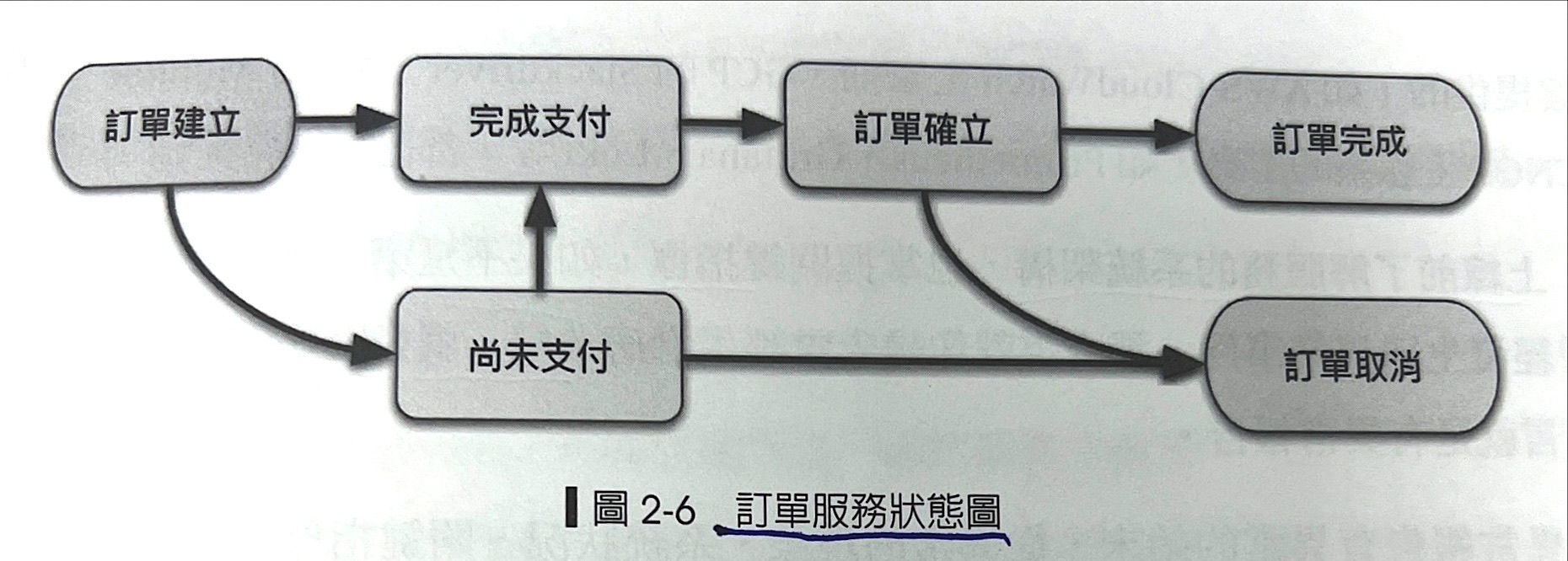
- 訂單建立總數
- 完成與未完成支付個別數量
- 訂單確立
- 訂單完成
- 訂單取消
直接列表統整、聚合計算成新的指標
系統關鍵指標
- 資源使用率:CPU、Memory、Disk Size
- I/O狀態:Network I/O Throughput、Disk的IOPS
- 網路層:Load Balancer 的 HTTP 5xx、4xx、3xx、2xx數量
- 內部服務的通訊:API對DB的QPS(Query Per Secend)、對Queue的操作請求
- 服務對外的通訊:RPS(Request Per Second)、HTTP 5xx、4xx、3xx、2xx數量
透過這些觀測系統關鍵指標可以了解整體異常狀態,對於業務的影響、當下處理辦法、事後改善都有實務上的參考,每次都是成長。
針對異常處理的經歷不是每位成員都有,親自下去處理是最快速成長的方法,因此了解與研究異常事件報告是讓沒有經驗的成員累積實力的最佳方法
2.2.4 上線中的穩健節奏
- 常規性交付(Normal Delivery)、計畫性交付、預期
- 大阪號
- 小版號
- 非常規性交付(Abnormal Delivery)、非計畫、非預期
- 嚴重異常與事件、需要緊急處理的,像是資安問題、嚴重的商業邏輯錯誤
- Web Services 會用 Hotfix處理
- 常規性維護、預期停機、計畫性維護、週期性
- Database Migration、作業系統升級、網路硬體升級
- 異動影響大、風險高,這種交付異動會選在離峰時間
上述的交付都有週期性或是穩定的輸出,可以使用行事曆的方式呈現。

2.2.5 上線後持續改善
- 週期性複查關鍵指標,依照實際狀況
調整系統警報水位,回到上面說的業務與系統指標 - 處理異常事件流程與分工
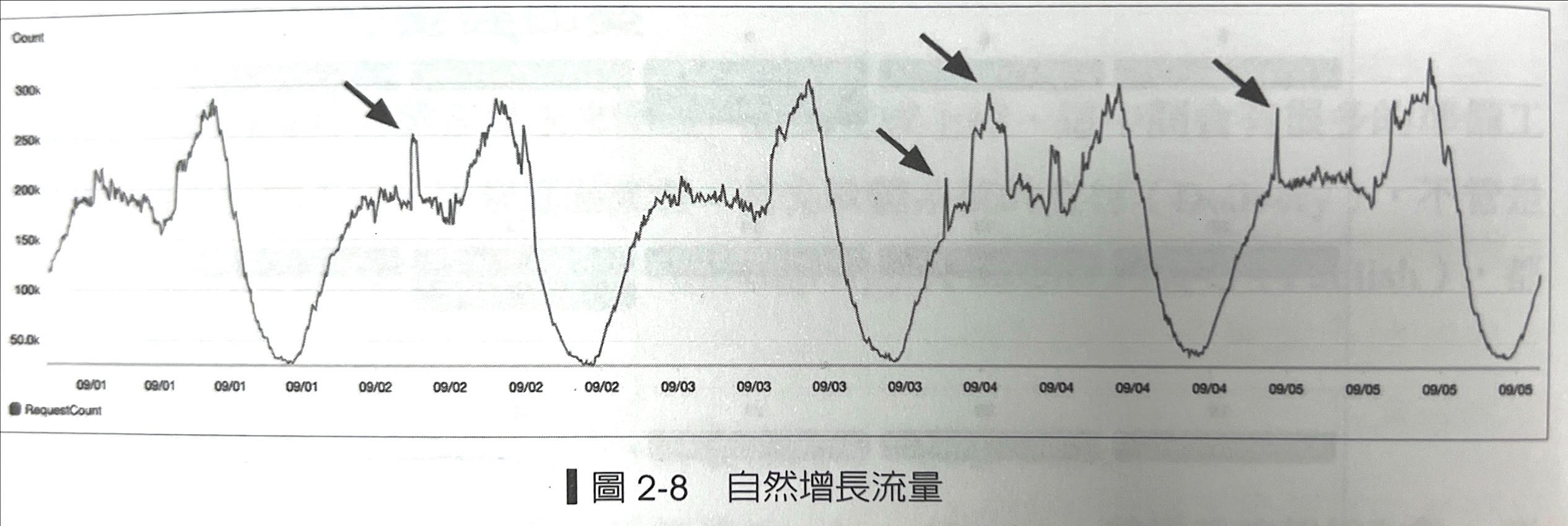
自然增長的趨勢都有週期性、每週都都有峰值、低谷,這些高高低低通常要定期複查,找到長時間的趨勢或判斷是否有異常。
每週複雜是穩定的節奏,一年52週反覆持續複查系統指標狀況。,最重要的是透過長期觀察了解系統的【正常】是什麼,接下來才有辦法定義【不正常】,這樣才有辦法觀察出報警水位,而這類的指標會跟著業績改變。
Operation Master
OB需要這個角色
如果當權者沒有時時刻刻在旁督促團隊容易鬆散,更別說飛輪效應。
而實務上主管又是組織裡的瓶頸,因為職務的關係常常要開會,很難協助團隊自主運作,導致所有的理念想法都無法實現。
基於這樣的因素需要有一個角色代替主管推動維運制度得運作,這個角色完成代理主管的工作,推動自組織運作,把方法與制度,購拓自組織的方式形成一個有框架依據,這個過程背後就是在培養下一個Lead、主管
列出前中後、框架作為提案
OM的工作是要引導維運團隊進行例行性任務,也就是前面提到的前中後的準備,更重要的是擔任團隊的協調角色,確認任務的範圍、輕重緩急,逐步修正、調整維運運作的框架,把XYZ定義出來並透過迭代、改善,最後統整出團隊適合的制度。
2.3 制度:Scrum、Kanban、Waterfall
可以並行,沒有排擠效應
Scrum
週期之內、穩定交付、快速失敗、快速修正。
一到兩週的Sprint, 每日站立會議、衝刺計畫、衝刺檢討、回顧會議、改進會議
......... 這邊時間關係先沒寫
Kanban
Waterfall
制度:值班還是待命
待補
3. 團隊的介面,合作共創
待補
4.事件管理
4.1 讓組織對異常事件有一致性的理解
沒有事件管理的狀況雜亂無章,溝通成本高
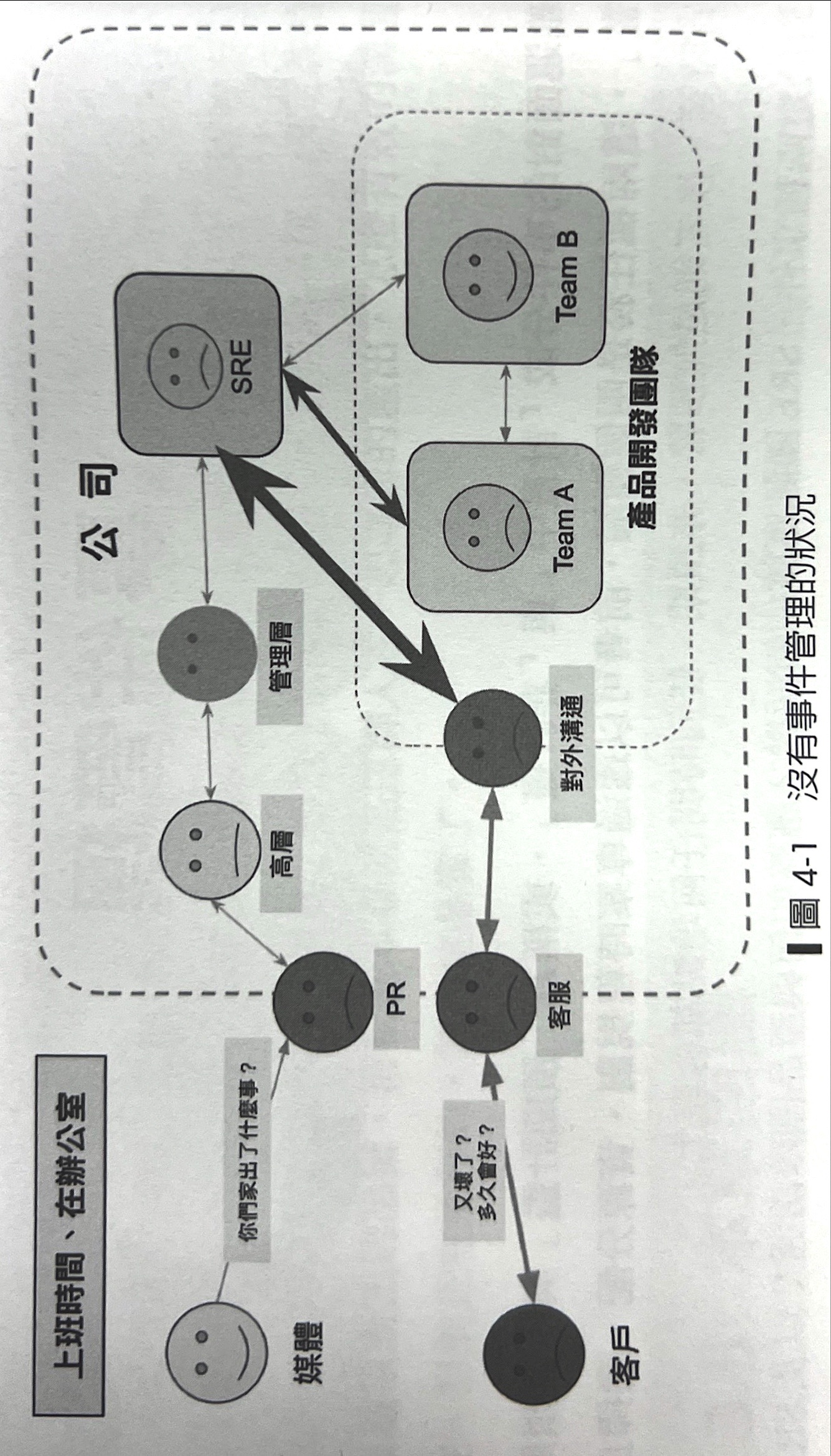
權責與分工不夠清晰
- 輕重緩急不分:嚴重性沒有適當的判斷
- 通知方式雜亂:管道沒有搜練、情報分散與碎片化,執行單位不知道要聽誰的
- 誤報:訊息太多,狼來了現象,最後沒人看(洗板、資訊爆炸)
- 分工不清:高層直接面對工程師下指導棋、或瘋狂對一線工程師追進度
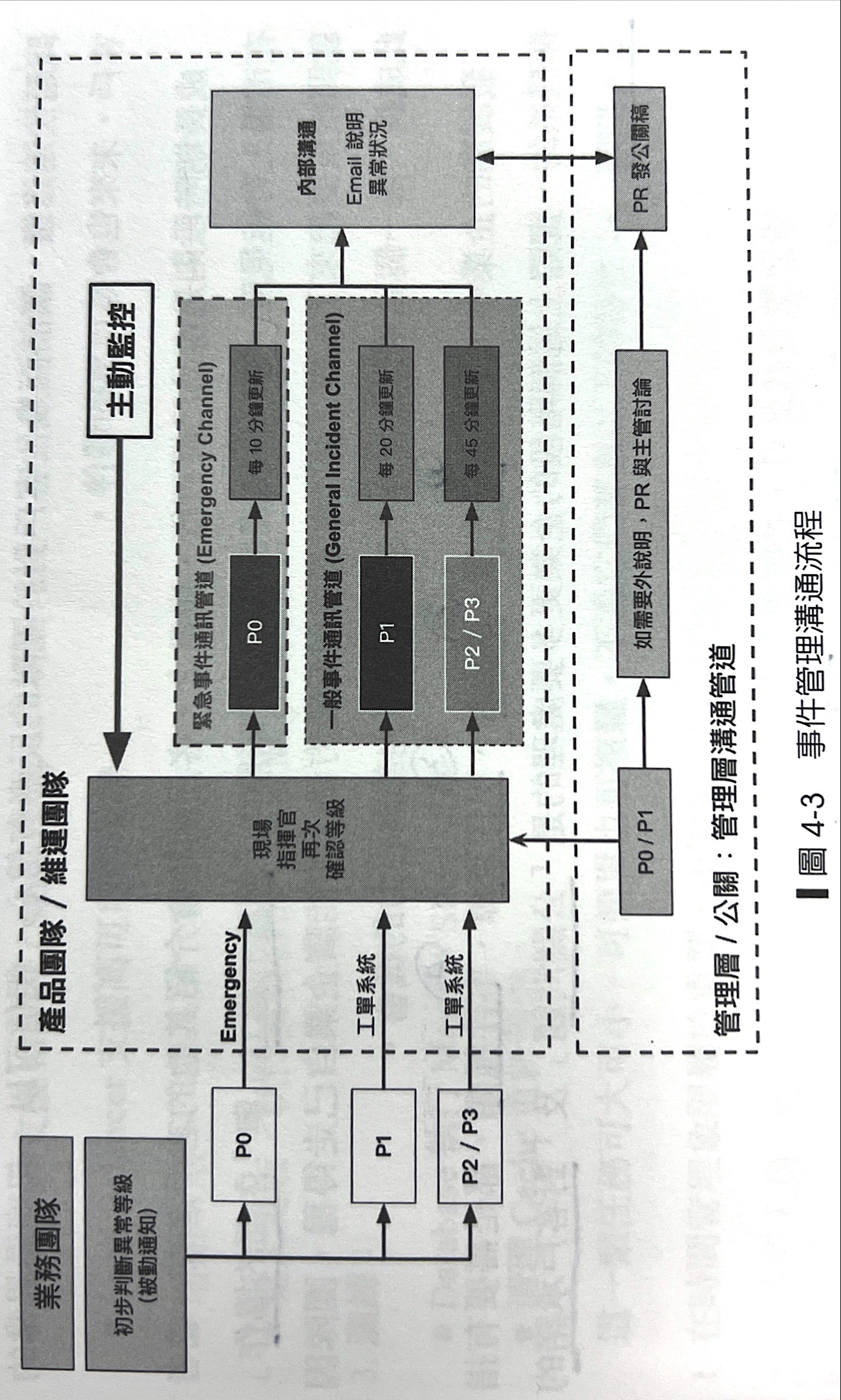
4.1.2 事件結構
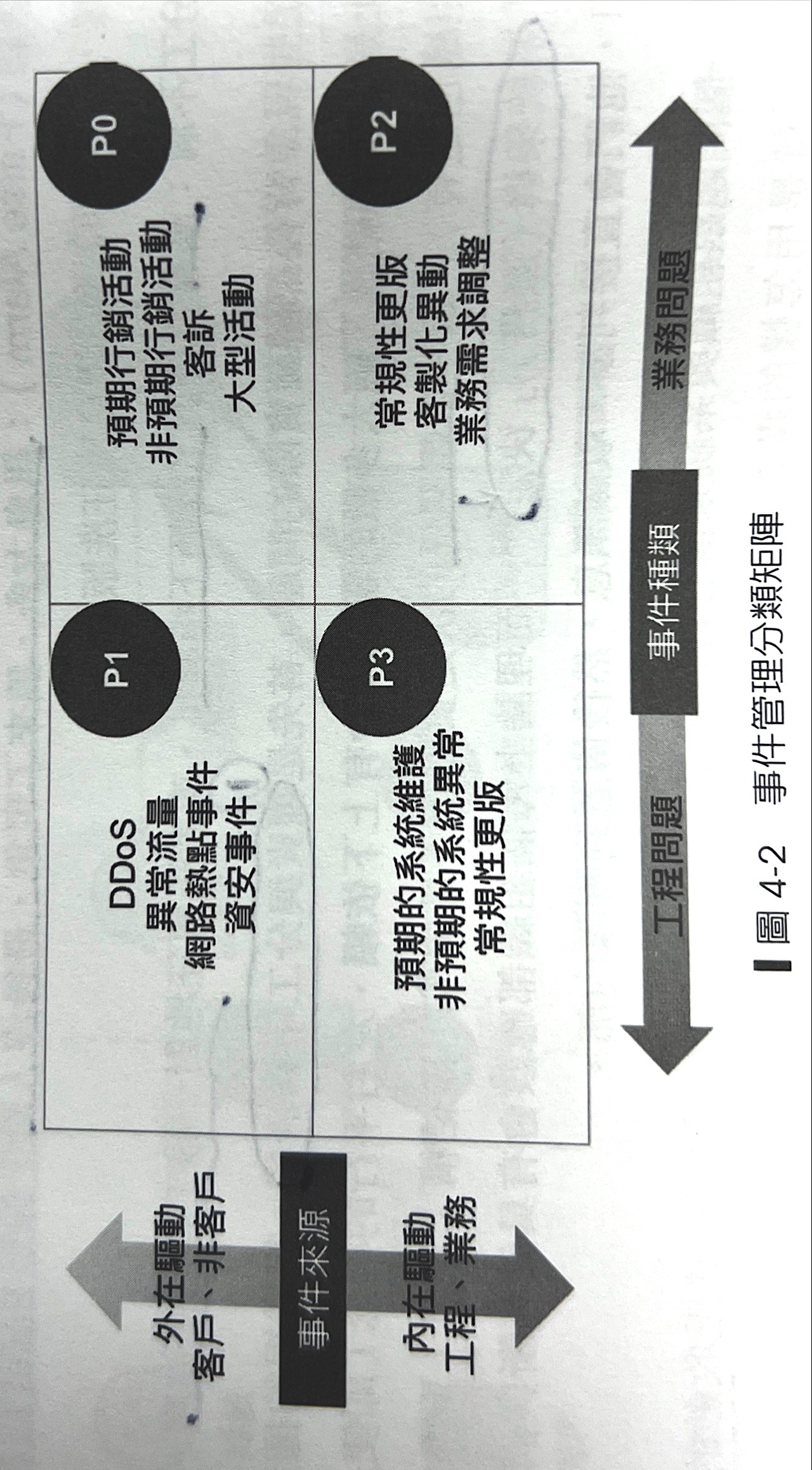
- p0 客訴處理(10分鐘更新進度):由業務維運第一線處理。如重大活動、客訴需要搭配【公關與危機管理】,擬定內外應變計畫。
- p1 工程問題(20分鐘更新進度):由SRE監控發現與處理,像是異常流量、DDOS攻擊、網路熱點事件
- p2 內部工程問題(45分鐘更新進度):開發過程常規性異動,如交付流程與部署沒有處理好、k8s出現異常。
- p3 內部維運問題(45分鐘更新進度):維運工程團隊的工作項目,自發性的驅動、非預期的驅動。
TODO:定義出P1~3的等級與事件後才有辦法定義出處理時間。
團隊要一起列出過去曾經發生的具體異常事件,判斷優先次序、事件種類、事件來源,每季重新整理一次。
考慮的屬性
- 優先序
- 嚴重性
- 事件來源
- 事件種類
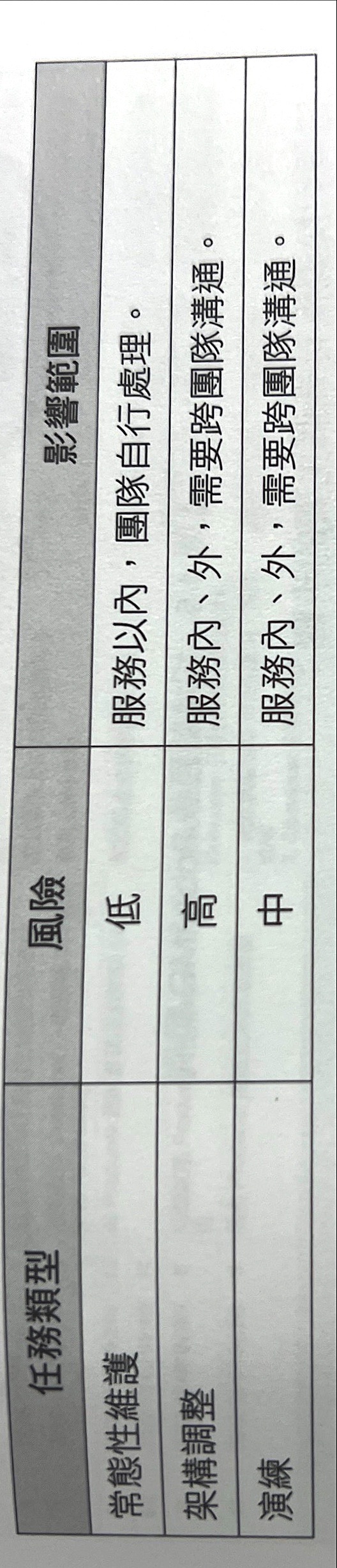
4.2 計畫中的事件(重要,不緊急)
- 常態性維護
- API Server的OS升級,上Security Path
- 更新Container Base Image、VM備份
- Storage執行容量擴充清理任務
- 硬碟汰舊換新
- 架構調整
- API支援 Auto Scaling
- DB支援Master/Slave架構
- Load Balance支援高可用性
- 增加WAF
- 重大更板、執行資料合併(Data Migration)
- 演練
- DB執行切換 Master/Slave切換
- 清理快取重新預熱
4.2.1 計畫:充分準備,讓大家有信心面對變化
以下是計畫性任務要考慮的項目
- 影響範圍:內部?依賴的服務?整個產品影響?
- 執行時間:早上、晚上、周末、放假前?
- 協作調度:動用多少人、資源?角色定義?指揮管?通報上級?
- 作業流程:執行劇本(Runbook)、敗部復活(Rollback)流程
- 配套資源:早餐、交通、補休
案例分享
第一案例:
用WebAPI更新作業系統為例子,Ubuntu 18.04生到20.04,或Container的Base Image換成Open JDK18。
更新範圍:Service Ninja
對外影響:End User
更換過程只要一個一個倫著更換、上下LB,基本不會有影響
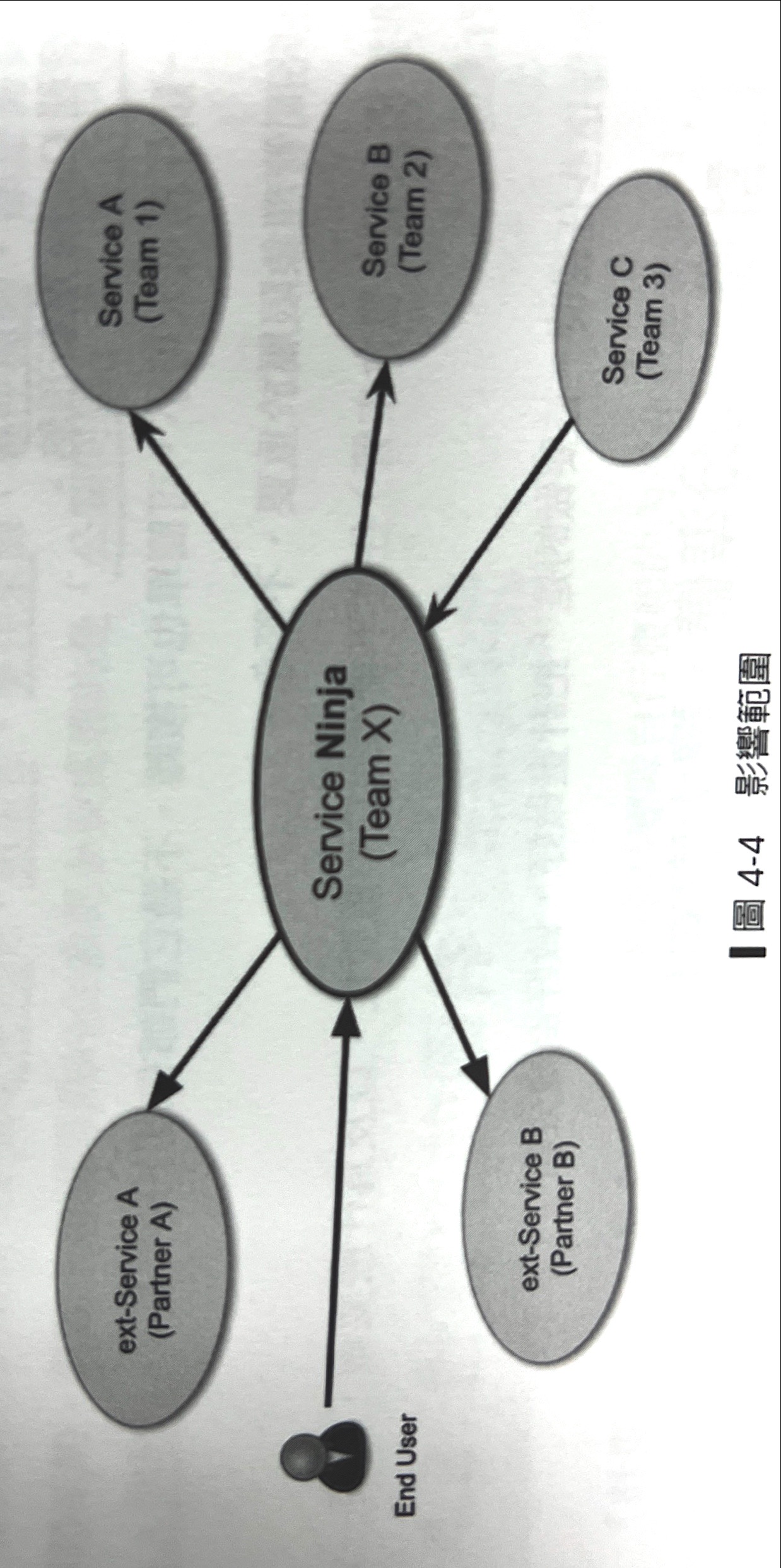
第二案例
架構調整DB支援HA架構,從原本一台機器變成兩台機器或以上,大多需要重新配置設定檔案,重啟動機器,讓資料同步,連線端需要改寫連線方式,重啟讓應用程式生效,過程可能短暫的中段,甚至抄寫副本過程IO量體大,造成反應速度慢,直接影響到 End User或Service C
下圖參考三個案例整理
4.2.2 影響範圍:了解系統架構
4.2.3 作業流程:執行劇本、敗部復活
4.2.4 執行時間:良辰吉時
4.2.5 協作與調度:R&R、團隊與溝鼟
4.2.6 配套措施
非預期事件與異常處理方法
4.3.1 緊急程度與決策矩陣
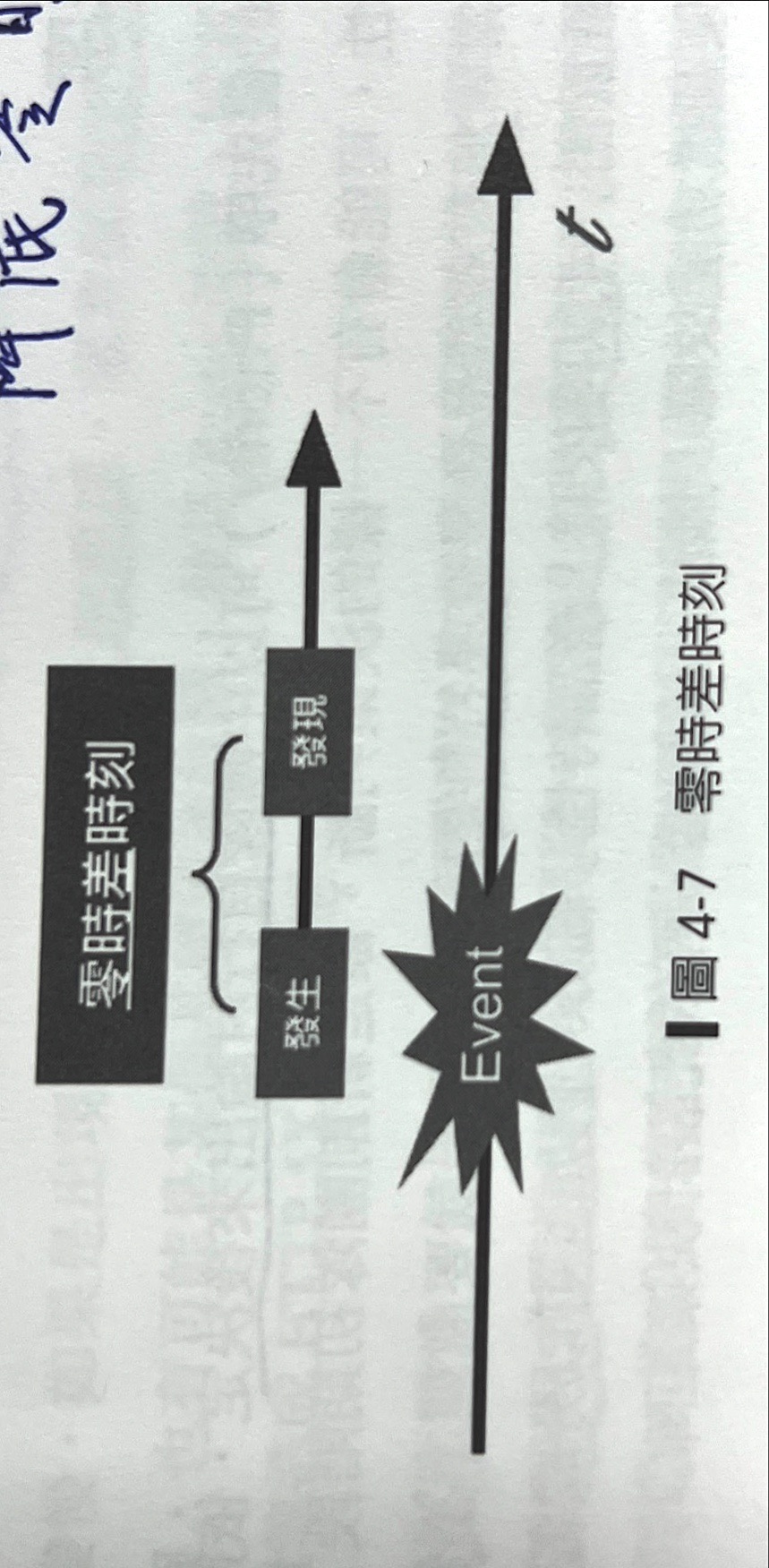
零時差時刻
發生時間是故障的第一時間,從那一個時間點系統出現狀況,狀況可能經過【間康檢查機制發現】或【被內部人員發現】或【被客戶發現】。 從發生到發現稱為:零時差時刻。這段時間其實沒有人知道系統已經有異常,這時間如果越長,會直接影響業務,損失越大。
嚴重性
用影響範圍決定問題的嚴重性,最後把嚴重性 + 發生的時間點搭配,產出優先順序。
- 個案
- 通例
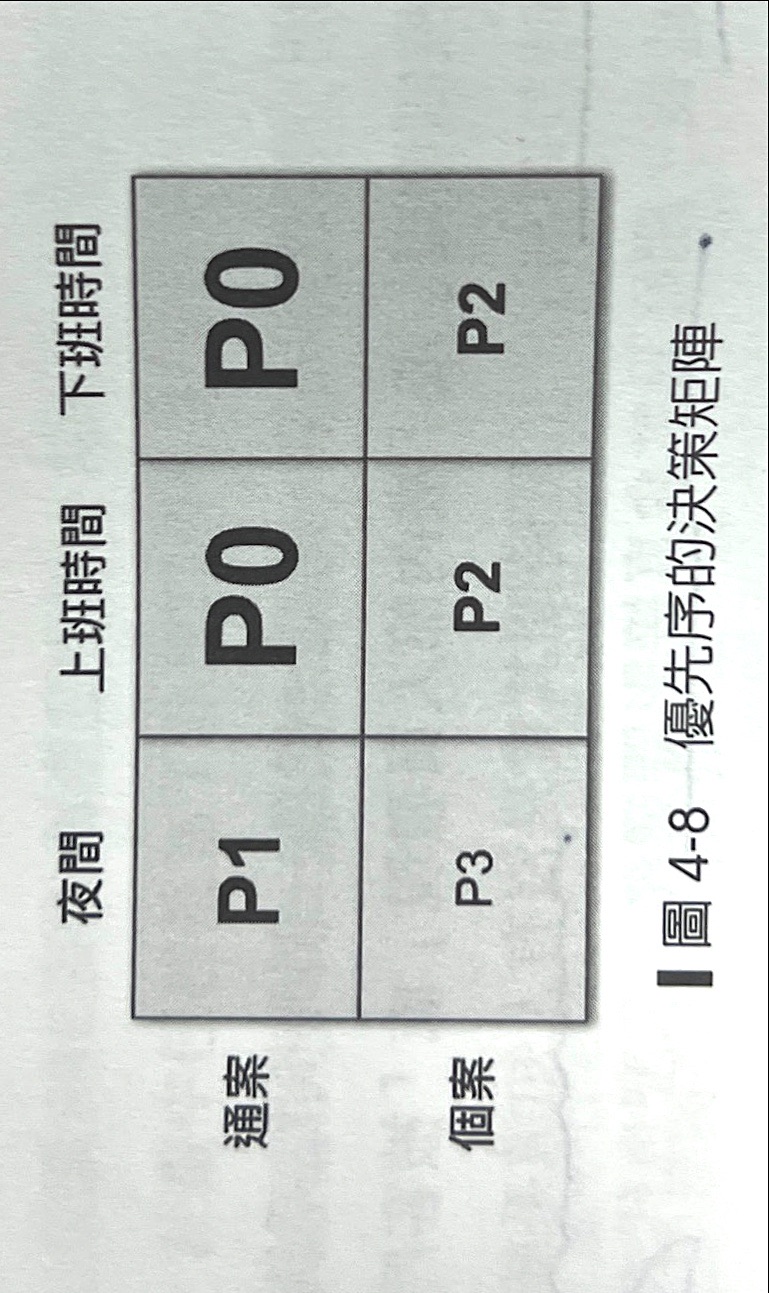
優先順序由團隊討論,根據公司產品特性。
4.3.2 從發生到發現:止血
對SRE來說,處利止血的方法大多是透過系統指標呈現的現象來調整資源或分流,更多時候是先跟產品團隊確立是否有更版。
幾個層面思考:系統反應時間變長、CPU使用率變高、I/O是否有關、DB察遜變慢、讀取檔案變慢、跨服務的API反應變慢。
HTTP 5xx錯誤是否變多、Redis故障、檔案系統故障、DB故障。
如果反應變慢、CPU沒有變高、基礎設施又沒錯,可能是應用程式本身的問題,同步或非同步控制沒做好出現I/O Blocking,造成請求空轉。
整個止血的過程要點式基於計畫中事件的訓練,包含系統架構、了解業務場景、明白系統得內外不依賴服務、清楚知道流量與量體的關係。
4.3.3 止血無效的行動:現場調查
針對SLA、SLO還是持續無法解決就只能現場直接解決,無法評估具體時間、範圍,只能成立戰情室一一了解狀況。
重大事件無法找到原因在列出時間軸
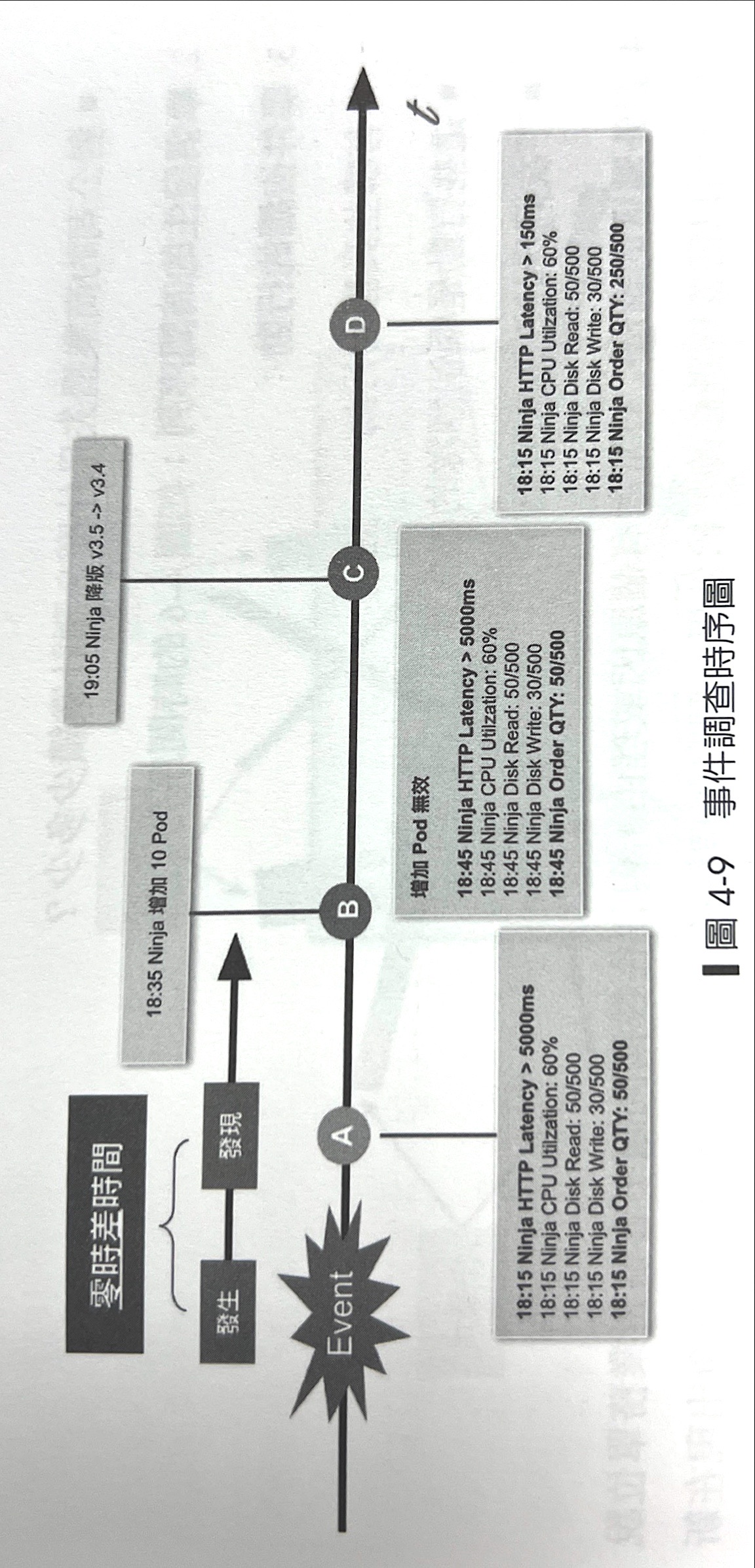
4.3.4 事件中的溝通:對內、對外
- 對客戶的影響:個案還是通例?
- 事件發生的時間畜
- 事件後續的行動
- 對外溝通的說法
- 溝通窗口
4.4 從失敗中學習:訓練與事件報告
具體報告內容
- 事件當下的紀錄
- 事後處理與修復
- 統計與分析

事後處理與修復
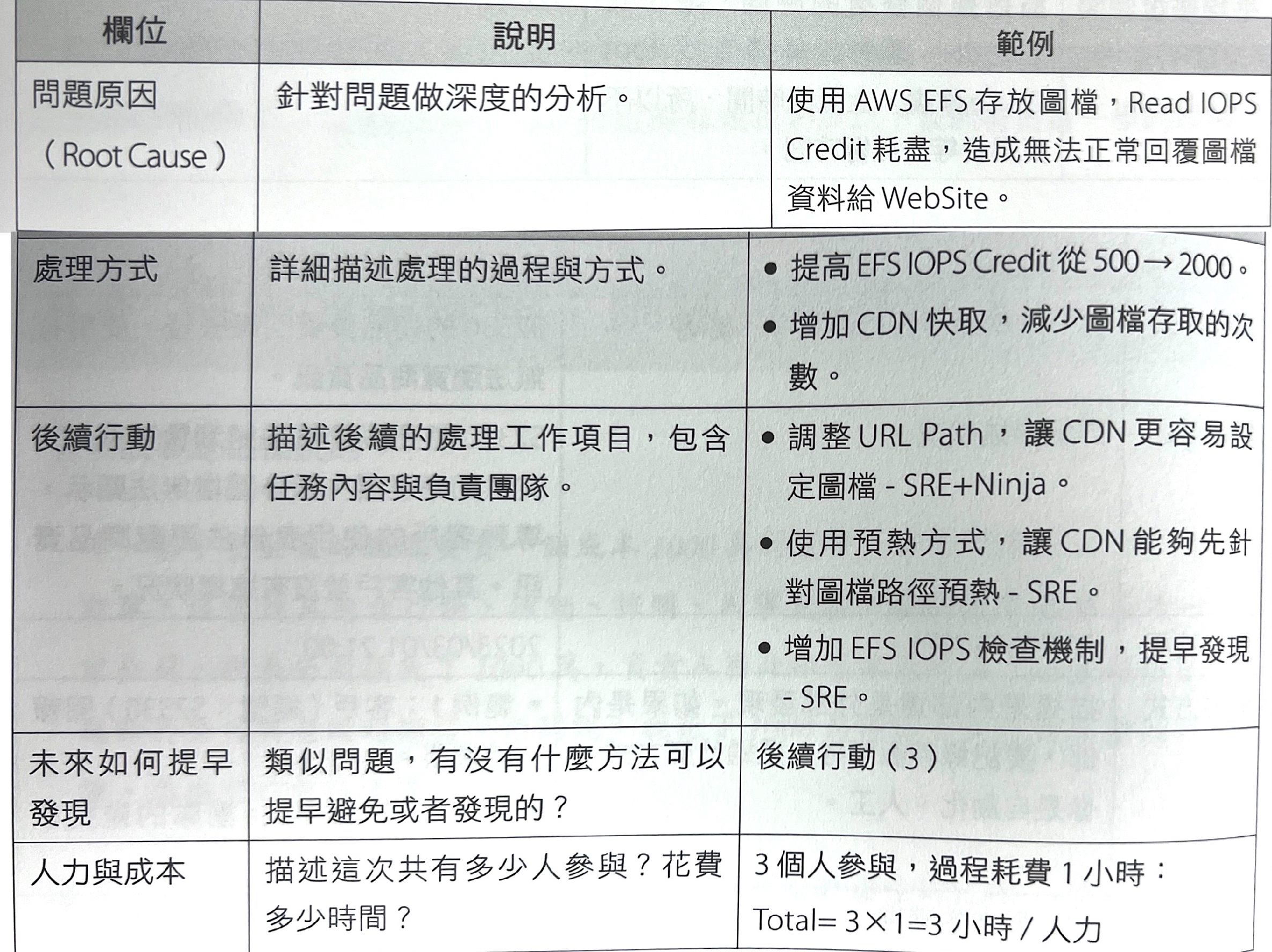
摘要報告

重點在於平常就沒有做好功課,平常就要蹲好馬步,在沒有時間與空間的限制狀況下,才能做到從容以赴,當非預期事件發生才有辦法臨場發揮的能力。太過於依賴SOP的話,背後的意義就是【無法獨立思考與獨立處理】。
開發維運治理
graph BT;
classDef default fill:#ECECFF,stroke:#9369DB,stroke-width:2px,color:#000;
classDef yellow fill:#ffffde,stroke:#aaaa33,stroke-width:1px;
A[規則1];
B[規格2];
C[規則3];
D[規範];
E[制度-人事物的邊界 ];
F[臨時辦法+時間];
G[原則];
A & B & C -->D;
F --歸納--> D & E;
D & E --抽象--> G;
- 多項規則產生規範
- 解決臨時問題的辦法 + 時間的醞釀調整,成為規範或制度
- 規範跟制度的抽象產生原則
人治與法治
法治會跟著公司走
人治處理人的情緒,需要高情商、手段,處理三次就產生臨時辦法
以上筆記是來自於:SRE實踐與開發平台指南